


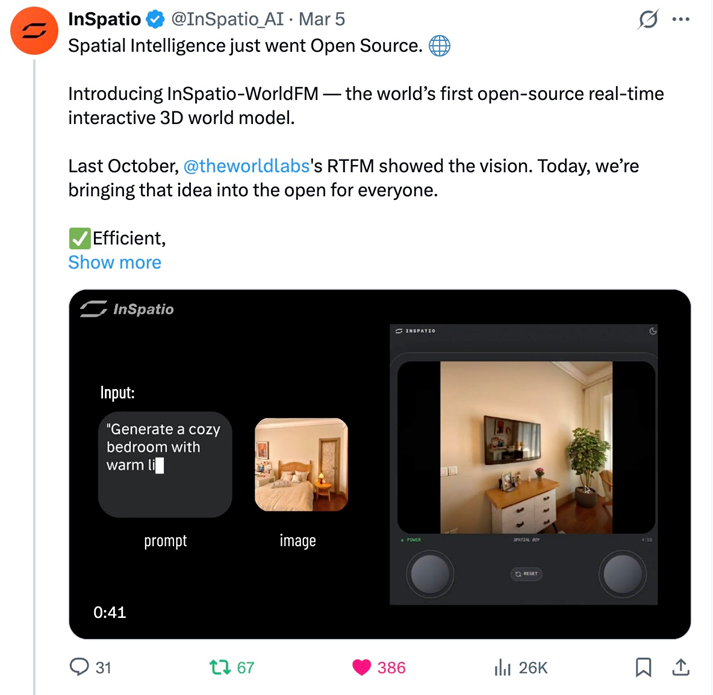
Recently, a research team led by Professor Guofeng Zhang from the College of Computer Science and Technology at Zhejiang University officially released and open-sourced a real-time frame generation model called InSpatio-WorldFM. Since its launch, the project has attracted widespread attention in the open-source community. Its GitHub repository has already garnered over 600 stars, sparking active discussions among developers and tech media both in China and internationally.This real-time, interactive 3D world model demonstrates distinctive technical advantages in the field of spatial intelligence and also serves as a compelling example of translating academic research into real-world applications.
Spatial intelligence is widely regarded as a key direction for the future of AI. However, intelligent agents still face significant challenges in perceiving and interacting with both virtual and physical environments. In 2024, World Labs, founded by Fei-Fei Li, introduced the real-time generative world model RTFM, offering a new approach for enabling agents to better understand the physical world.Building on this context, Professor Zhang Guofeng and his team have made a breakthrough in spatial intelligence technology with the introduction of the real-time frame generation model InSpatio-WorldFM.
Giving AI a 3D Brain
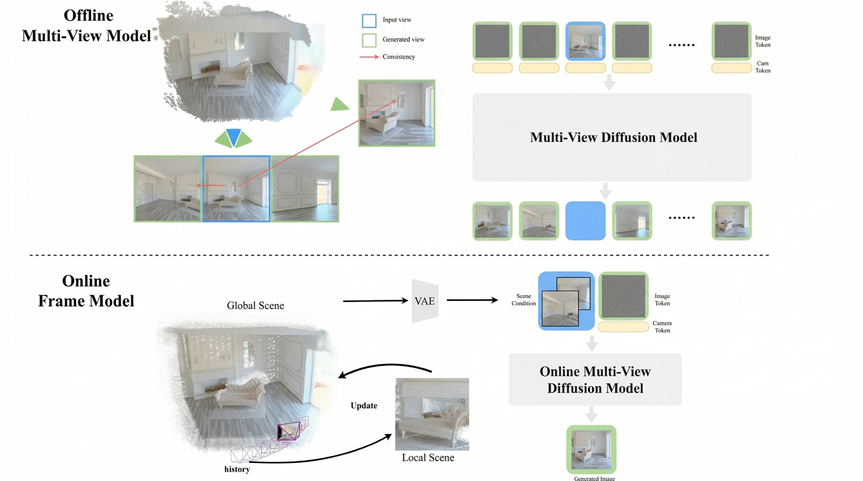
Backed by over two decades of research in 3D vision and spatial computing led by Prof. Zhang Guofeng, the team moves beyond the traditional reliance on native 3D data. Instead, they introduce a novel approach combining data up-lifting and geometric constraints to extract 3D spatial knowledge from vast amounts of 2D internet video.
The resulting model performs multi-view consistent spatial reasoning, supports real-time interactive exploration, and generates virtual worlds that remain stable in geometry and lighting. Even over long inference horizons, it avoids the common issues of memory loss and degradation.
Breaking the Compute Myth: Training a 3D World Model with Just 100 GPUs
In an era where large models often require clusters of tens of thousands of GPUs, the team demonstrates remarkable efficiency. Their proprietary data up-lifting strategy distills 3D knowledge from massive 2D video datasets, enabling rapid training and iteration of a 3D world model using only 100 GPUs (with even stronger performance in the newly open-sourced version).
The model not only allows free navigation within generated scenes, but can also seamlessly transfer dynamic foreground objects from one video into entirely new environments. It preserves foreground details at the pixel level while ensuring strong consistency with the new background in terms of geometry, lighting, and physical rules—something most existing video models struggle to achieve.
Even more impressively, the model runs at 7 FPS on a single consumer-grade RTX 4090 GPU, opening up exciting possibilities for deployment on edge devices such as robots and XR (augmented reality) glasses.
Three Core Technical Advantages
01 — Beyond 2D: Stronger Spatial Consistency
By enforcing multi-view 3D consistency as a core constraint, objects gain true physical volume. The model remains stable over long durations without drift or deformation, effectively overcoming the temporal and spatial memory limits of 2D video models.
02 — Efficient by Design: Reduced Compute Requirements
A lightweight architecture—combining frame-based design, model distillation, and inference optimization—significantly reduces computational demands, making on-device deployment feasible.
03 — Novel Memory Architecture for Stable Reasoning
The model adopts a hybrid memory design of explicit anchors + implicit memory.
Feedforward reconstruction generates explicit physical spatial anchors, while reference frames serve as implicit memory, enabling stable, indefinite long-term reasoning.
Key Strengths
Alleviating the Scarcity of 3D Data
Building on expertise in SLAM, NeRF (Neural Radiance Fields), and 3D Gaussian Splatting, the team developed a proprietary 3D data up-lifting engine. This system synthesizes training data at low cost, extracts 3D knowledge from large-scale video, and leverages geometric constraint toolchains to overcome the bottleneck of limited 3D data.
Open Source for Global Collaboration
The team has open-sourced InSpatio-WorldFM, inviting developers worldwide to advance spatial intelligence together. It also serves as a foundation model for academic research in 3D scene generation. Further improvements are underway, with an upcoming version supporting dynamic video input and real-time interaction.
The open release of this real-time frame-generation model marks a new direction for spatial intelligence. It also exemplifies a successful end-to-end innovation pipeline—from fundamental research to core technological breakthroughs and real-world application—highlighting how cutting-edge spatial AI can be transformed into next-generation productive capabilities.
Resources
Project page: https://inspatio.github.io/worldfm/
GitHub: https://github.com/inspatio/worldfm
Demo: http://www.inspatio.com/worldfm
Technical report: http://arxiv.org/abs/2603.11911
