



A research team led by Professor Jin Xiaogang at the State Key Laboratory of CAD and Computer Graphics, Zhejiang University, has presented their latest work at SIGGRAPH 2025. The paper, titled "Text-based Animatable 3D Avatars with Morphable Model Alignment", introduces AnimPortrait3D-a novel framework for generating photorealistic, animatable 3D Gaussian-splatting avatars from textual descriptions, with precise alignment to morphable models.
This research makes two key technical contributions:
It leverages pre-trained text-to-3D priors to initialize the avatar with robust appearance, geometry, and consistent binding to a morphable model.
It uses semantic segmentation maps and normal maps rendered from the deformable model as conditions in a ControlNet to optimize facial dynamics, enabling accurate alignment.
The proposed method significantly outperforms existing approaches in synthesis quality, alignment precision, and animation fidelity — advancing the state of the art in text-driven 3D head avatar generation.
Background
Text-to-3D generation of high-fidelity, animatable virtual humans holds transformative potential in fields like gaming, film, and embodied AI assistants. A common pipeline combines parametric head models with 2D diffusion models via score distillation sampling to ensure 3D consistency. However, existing methods often suffer from unrealistic detail and misalignment between appearance and driving parameter models, leading to unnatural animation results.
These challenges stem from two core issues:
Ambiguity in diffusion outputs: A single text prompt can correspond to a broad image distribution in diffusion models, resulting in weak constraints on appearance and geometry. This can lead to artifacts like the “Janus problem,” where avatars exhibit unnatural symmetry or blurring. Prior approaches attempted to mitigate this using joint appearance-geometry priors but still struggled with noisy geometry and lacked animation support.
Poor alignment between diffusion outputs and parametric models: Existing techniques often fail to ensure robust alignment, causing artifacts during animation. While facial landmark-based ControlNet guidance has been explored, relying solely on sparse 3D landmarks proves inadequate. The fundamental challenge lies in incorporating both geometric and semantic information from the parametric model into the optimization process.
Innovation and Contributions
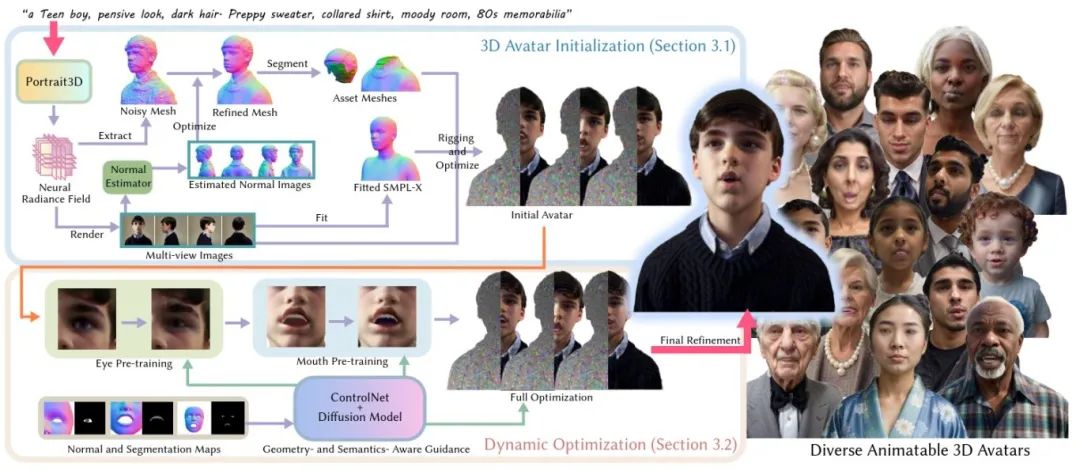
The proposed AnimPortrait3D framework enables text-driven generation of animatable 3D avatars with photorealistic appearance, accurate geometry, and precise alignment to parametric meshes. The method is composed of two key stages:
Initialization: It begins by transferring high-quality appearance and geometric priors from an existing text-to-static-3D face model, with animation support built on the SMPL-X model. Hair and clothing — not explicitly modeled by SMPL-X — are extracted using normal-based mesh filtering and semantic segmentation, then integrated into the Gaussian representation. This stage ensures high visual fidelity and a solid base for animation.
Dynamic Optimization: To overcome animation artifacts from static generation, a ControlNet trained on normal and segmentation maps from SMPL-X provides joint geometric-semantic guidance. For complex regions like eyelids and mouth, specialized strategies are employed:
For eyes, high-precision references are generated via diffusion and ControlNet to refine geometry and texture.
For the mouth, an Interval Score Matching (ISM) loss is introduced to enhance dynamic texture detail under expressive conditions.
Final refinement includes global optimization with ISM loss and diffusion-based image enhancement to suppress residual artifacts.
Key Contributions:
A novel multi-stage framework for generating animatable 3D avatars from text, delivering state-of-the-art synthesis quality and animation realism.
A new initialization strategy that jointly models appearance and geometry, ensuring stable bindings to morphable models and facilitating reliable animation control.
A dynamic pose optimization method guided by geometric and semantic signals via ControlNet, enabling high-precision alignment across expressions and poses.
Results and Comparisons
Extensive experiments benchmark AnimPortrait3D against leading methods such as HeadStudio, TADA, and HumanGaussian, as well as editing models like PortraitGen and reconstruction methods GPAvatar and GAGAvatar.

Qualitative results show that AnimPortrait3D excels in challenging areas such as hair strands, eyes, and mouth dynamics. ControlNet integration improves the fidelity and control of expressions, while the robust initialization preserves detail across various viewpoints, including difficult rear angles.
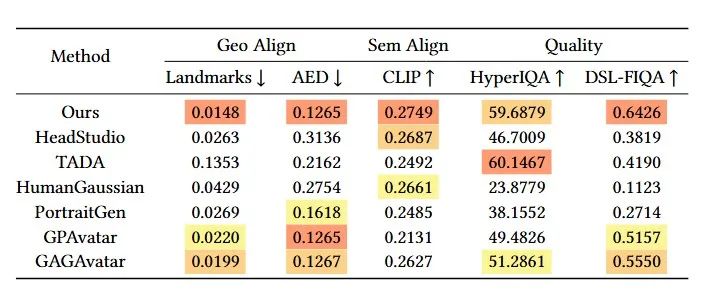
Quantitative comparisons were conducted using 20 standardized text prompts (10 male, 10 female). Each method rendered 100 images per avatar from randomly sampled views and expressions using parameters from the NeRSemble dataset. AnimPortrait3D outperforms or matches the best-performing methods across key metrics.
Acknowledgments
This work was led by Professor Jin Xiaogang of Zhejiang University, with PhD candidate Wu Yiqian as the first author. Wu completed the research during a visiting period at the Computer Vision and Learning Group at ETH Zurich, under the joint supervision of Professor Siyu Tang and Professor Jin. The second author, Malte Prinzler, is supported by the Max Planck ETH Center for Learning Systems (CLS).
The research was funded by the Key R&D Program of Zhejiang Province, the National Natural Science Foundation of China, and the Swiss National Science Foundation.
